算法笔记:跳表(r1)
skiplist
目录
这是读书时一篇旧文搬运.几年后再次回顾下算法.
跳表是一种著名数据结构。
原理应该不用介绍了,rocksdb/redis内部都有使用skiplist。
相对于红黑树,它的优势我认为是实现简单,并且容易无锁化。
本文主要讨论:
- skiplist一些性质分析
- skiplist核心思想&核心问题
- rocksdb中的跳表实现分析
skiplist原理
property of a node
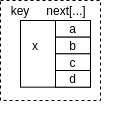
a node of skiplist
-
性质1:
- Q:给定某个skiplist的节点$x$,其含有以下4个level的next值:a(lvl=3),b(lvl=2),c(lvl=1),d(lvl=0),问:x,a,b,c,d之间满足什么关系?
- A: $$ a > b > c > d > x $$ (是否带等号看具体实现), 且lvl指向的子链表含有的元素的范围是 $$(next[lvl],next[lvl+1])$$
-
性质2: L0层节点是整个跳表的所有数据,每上一层都是前一层的子集。
key-idea
- 跳表 = 有序链表 + 索引节点
- 查找:利用索引,理想状态下可以达到
logn级别复杂度。- 给定key的查找过:需要从最高level开始,逐步下降,直到lvl=0,每下降一个level就缩小了查找区间的范围。
- 插入/删除:如果该节点涉及多个level,需要变更所有level的前驱和后继。
实现细节:
-
思路就是每一层都是一个有序链表,lvl+1层是lvl层的索引。(索引本身也是数据)
-
给定一个key值,可以找到一个前驱数组
prev[...](所有level比key小的最后一个节点)。 -
任意前驱数组元素prev[i],满足性质: $$ 对于 i \in [0,currmax], 有: \
prev[i].key < key \qquad 且 \
prev[i].next[i] > key 或 prev[i].next[i] == null \
$$ (PS:给定key和某skiplist,每一层应该只有1个这样的节点)
rocksdb的skiplist
rocksdb的memtable的几种实现
(or 表示方式representation)
- skiplist
- inlineskiplist *(by default)
- hash-skiplist
- hash-linklist
- vector
skiplist的实现
-
两个参数默认值: int32_t max_height = 12, int32_t branching_factor = 4
- 值得一提的是,其中
branching_factor取4的话,正好对应论文里的P = 0.25,即生成的新节点为level+1的概率是level的1/4,。(PS:level=1的概率是1)
- 值得一提的是,其中
-
skiplist节点内部核心数据:next指针数组
- 数组长度是该节点的level,实现上采用了一个c里常见的
struct hack+placement new
- 数组长度是该节点的level,实现上采用了一个c里常见的
-
核心流程是查找,查找这里采用了双指针法,即给定key值,每次对比
curr和curr->next看curr是否为key值在本lvl的前驱,若是,记录下,然后迭代到下一个lvl(lvl-1),缩小范围继续下一轮。 -
线程安全性
- skiplist节点内部指针均采用原子变量,原子变量的同步依赖于
acquire/release语义(而没使用锁)
- skiplist节点内部指针均采用原子变量,原子变量的同步依赖于
-
fast-path-for-seq-insert
- 利用上一次保存的prev数组,可以实现较快插入顺序元素(不需要再次构建一遍前驱数组)
-
inlineskiplist:
- 实际上rocksdb的memtable使用的是
inlineskiplist(而没有用skiplist,which在leveldb里采用)
- 实际上rocksdb的memtable使用的是
几个疑问
- 对于std::atomic这种非POD类型,也能玩这种
struct hack吗? - 利用原子变量进行无锁化,需要十分注意memory-order, 那么acqure-release语义到底是什么东西?
- 其他几种memtable的实现优劣?
这些超出本文讨论范围了,下次在讨论罢。
Reference
- struct hack - flexible array. https://stackoverflow.com/questions/36577094/array-of-size-0-at-the-end-of-struct